
An AI Journey with Qwen, RAG, and LangChain
This article delves into the revolutionary concepts of Qwen, Retrieval-Augmented Generation (RAG) and LangChain.


In the era of Artificial Intelligence (AI), extracting meaningful knowledge from vast datasets has become critical for both businesses and individuals. Enter Retrieval-Augmented Generation (RAG), a breakthrough that has turbocharged the capabilities of AI, empowering systems to not only generate human-like text but also pull in relevant information in real-time. This fusion produces responses that are both rich in context and precise in detail.
As we set sail on the exciting voyage through the vast ocean of Artificial Intelligence (AI), it's essential to understand the three pillars that will be our guiding stars: Generative AI, Large Language Models (LLMs), LangChain, Hugging Face, and the useful application on this RAG (Retrieval-Augmented Generation).
Large Language Models and Generative AI: The Engines of Innovation
At the core of our journey lie Large Language Models (LLMs) and Generative AI - two potent engines driving the innovation vessel forward.
Large Language Models (LLMs)

LLMs, such as Qwen, GPT, and others, are the titans of text, capable of understanding and generating human-like language on a massive scale. These models have been trained on extensive corpora of text data, allowing them to predict and produce coherent and contextually relevant strings of text. They are the backbone of many natural language processing tasks, from translation to content creation.
Generative AI (GenAI)
Generative AI is the artful wizard of creation within the AI realm. It encompasses technologies that generate new data instances that resemble the training data, such as images, music, and, most importantly for our voyage, text. In our context, Generative AI refers to the ability of AI to craft novel and informative responses, stories, or ideas that have never been seen before. It enables AI to not just mimic the past but to invent, innovate, and inspire.
LangChain: Orchestrating Your AI Symphony
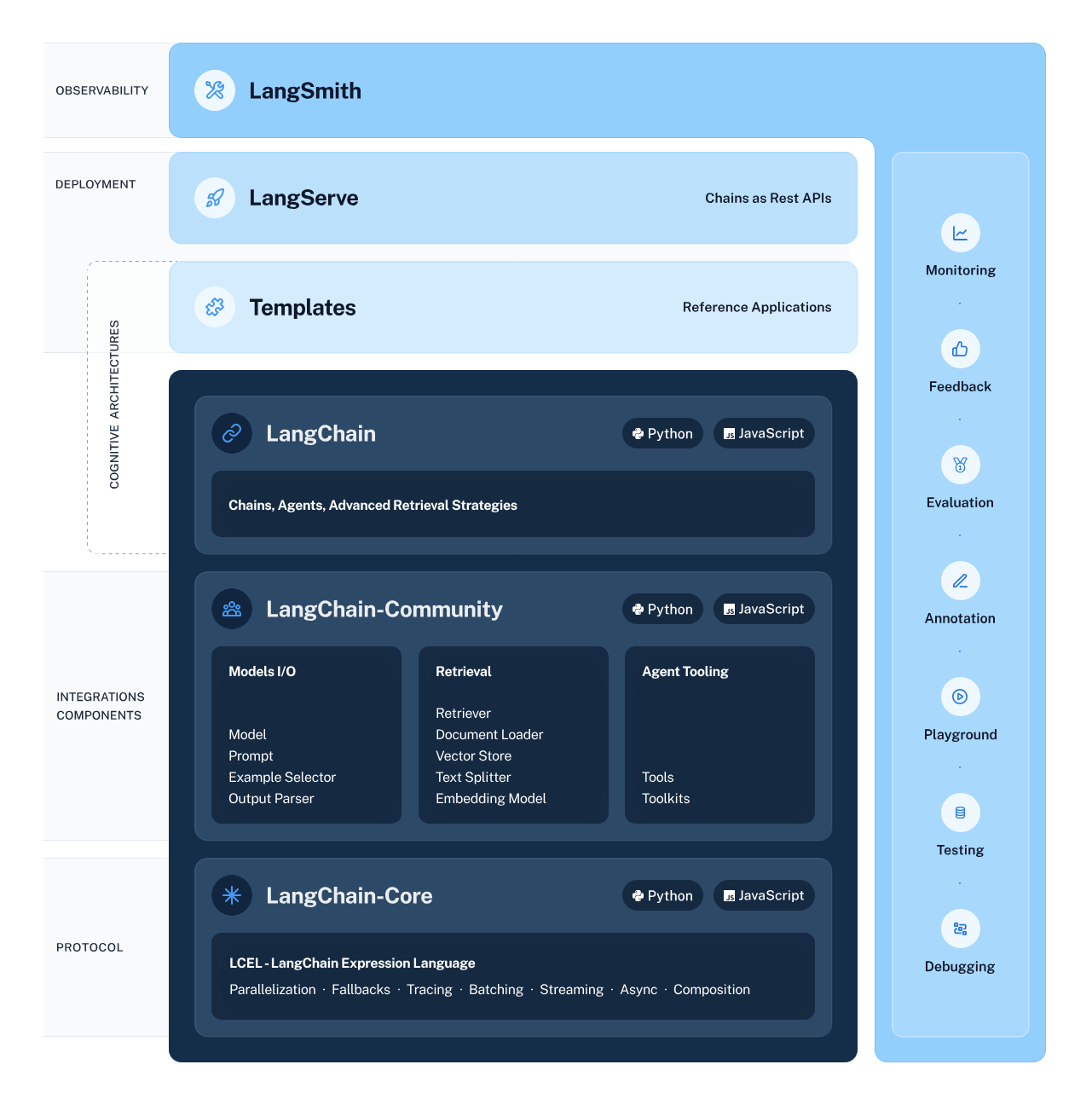
LangChain serves as the architect of our AI workflow, meticulously designing the structure that allows for seamless integration and interaction between various AI components. This framework simplifies the complex process of chaining together data flow from intelligent subsystems, including LLMs and retrieval systems, making tasks such as information extraction and natural language understanding more accessible than ever before.
Hugging Face: The AI Model Metropolis

Hugging Face stands as a bustling metropolis where AI models thrive. This central hub offers a vast array of pre-trained models, serving as a fertile ground for machine learning exploration and application. To gain entry to this hub and its resources, you must create a Hugging Face account. Once you take this step, the doors to an expansive world of AI await you — just visit Hugging Face and sign up to begin your adventure.
RAG: Harnessing Vector Databases for Accelerated Intelligence
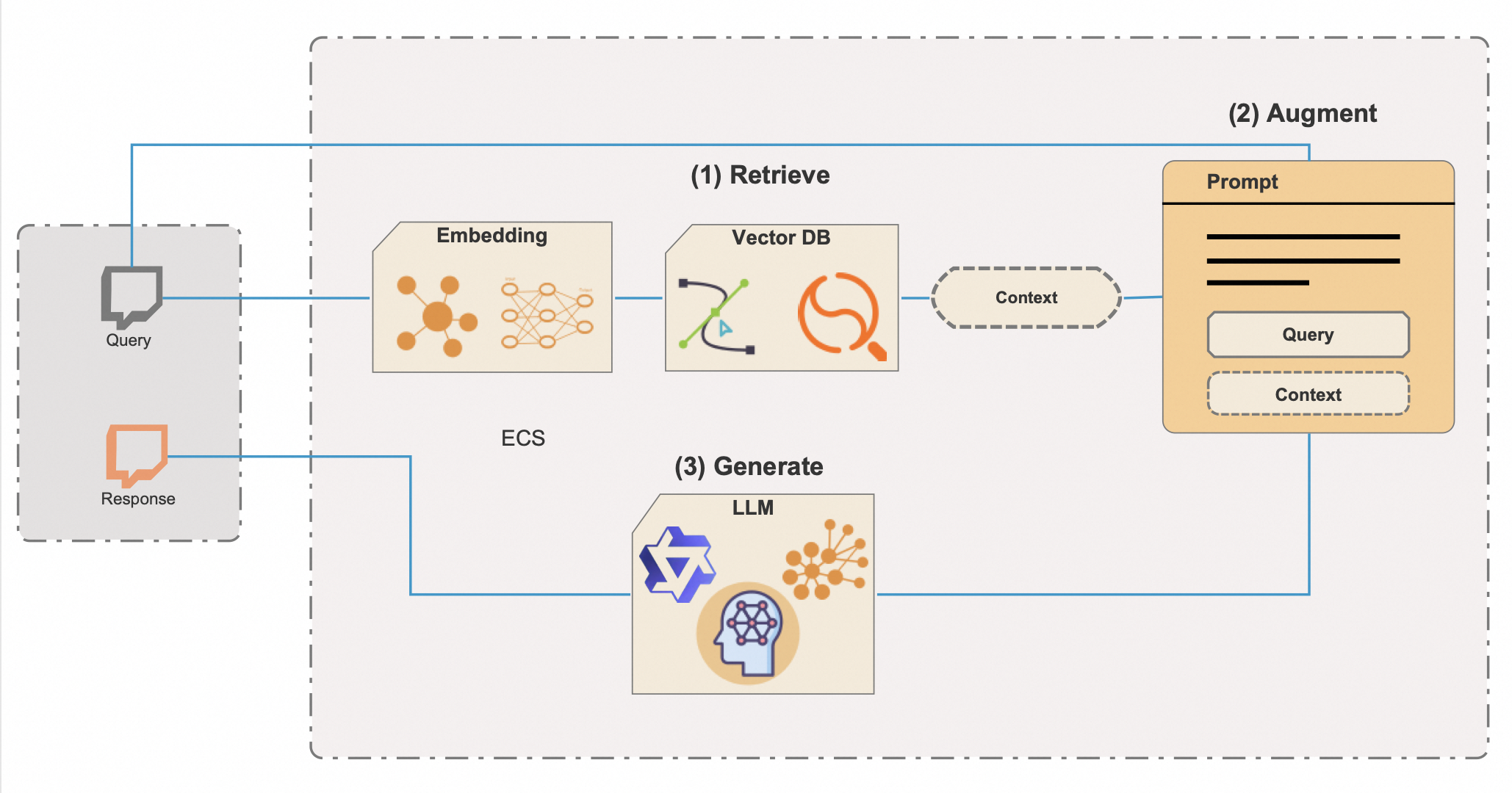
Retrieval-Augmented Generation (RAG) is a sophisticated AI technique that marries the inventive power of Generative AI with the precision of knowledge retrieval, creating a system that's not only articulate but also deeply informed. To unlock the full potential and efficiency of RAG, it integrates vector databases—a powerful tool for speedily sifting through vast information repositories. Here's an enhanced breakdown of how RAG operates with vector databases:
Retrieval withVector Databases: RAG begins its process by querying a vector database, which houses embedded representations of a large corpus of information. These embeddings are high-dimensional vectors that encapsulate the semantic essence of documents or data snippets. Vector databases enable RAG to perform lightning-fast searches across these embeddings to pinpoint content that is most relevant to a given query, much like an AI swiftly navigating a digital library to find just the right book.
Augmentation with Context: The relevant information retrieved from the vector database is then provided to a generative model as contextual augmentation. This step equips the AI with a concentrated dose of knowledge, enhancing its ability to craft responses that are not only creative but also contextually rich and precise.
Generation of Informed Responses: Armed with this context, the generative model proceeds to produce text. Unlike standard generative models that rely solely on learned patterns, RAG weaves in the specifics from the retrieved data, resulting in outputs that are both imaginative and substantiated by the retrieved knowledge. The generation is thus elevated, yielding responses that are more accurate, informative, and reflective of true context.
The integration of vector databases is key to RAG's efficiency. Traditional metadata search methods can be slower and less precise, but vector databases facilitate near-instantaneous retrieval of contextually relevant information, even from extremely large datasets. This approach not only saves valuable time but also ensures that the AI's responses are grounded in the most appropriate and current information available.
RAG's prowess is especially advantageous in applications like chatbots, digital assistants, and sophisticated research tools — anywhere where the delivery of precise, reliable, and contextually grounded information is crucial. It's not simply about crafting responses that sound convincing; it's about generating content anchored in verifiable data and real-world knowledge.
Armed with an enriched comprehension of LangChain, Hugging Face, LLMs, GenAI, and the vector database-enhanced RAG, we stand on the brink of a coding adventure that will bring these technologies to life. The Python script we'll delve into represents the synergy of these elements, demonstrating an AI system capable of responding with not just creativity and context but also with a depth of understanding once thought to be the domain of science fiction. Prepare to code and experience the transformative power of RAG with vector databases.
Begin Coding Journey
Before You Begin: The Essentials
Before we set sail on this tech odyssey, let's make sure you've got all your ducks in a row:
A Linux server is better with a GPU card – 'cause let's face it, speed is of the essence.
Python 3.6 or higher – the magic wand of programming.
pip or Anaconda – your handy dandy package managers.
if it is with a GPU card, then NVIDIA drivers, CUDA Toolkit, and cuDNN – the holy trinity for GPU acceleration.
Got all that? Fabulous! Let's get our hands dirty (figuratively, of course).
Running the Code
By carefully managing your Python dependencies, you ensure that your AI project is built on a stable and reliable foundation. With the dependencies in place and the environment set up correctly, you're all set to run the script and witness the power of RAG and LangChain in action.
Setting the Stage: Import Libraries and Load Variables
Before we can embark on our exploration of AI with the LangChain framework and Hugging Face's Transformers library, it's crucial to establish a secure and well-configured environment. This preparation involves importing the necessary libraries and managing sensitive information such as API keys through environment variables.
from torch import cuda
from langchain_community.vectorstores import FAISS
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_community.embeddings.huggingface import HuggingFaceEmbeddings
from transformers import AutoModelForCausalLM, AutoTokenizer
from langchain_community.llms.huggingface_pipeline import HuggingFacePipeline
from transformers import pipeline
from dotenv import load_dotenv
load_dotenv()
When working with AI models from Hugging Face, you often need access to the Hugging Face API, which requires an API key. This key is your unique identifier when making requests to Hugging Face services, allowing you to load models and use them in your applications.
Here's what you need to do to securely set up your environment:
Obtain Your Hugging Face API Key: Once you have created your Hugging Face account, you can find your API key in your account settings under the 'Access Tokens' section.
Secure Your API Key: Your API key is sensitive information and should be kept private. Rather than hard-coding it into your scripts, you should use environment variables.
Create a .env File: Create a file named .env. This file will store your environment variables.
Add Your API Key to the .env File: Open the .env file with a text editor and add your Hugging Face API key in the following format:
HUGGINGFACE_API_KEY=your_api_key_here
Replace your_api_key_here with the actual API key you obtained from Hugging Face.
Define the Model Path and Configuration
modelPath = "sentence-transformers/all-mpnet-base-v2"
device = 'cuda' if cuda.is_available() else 'cpu'
model_kwargs = {'device': device}
Here, we set the path to the pre-trained model that will be used for embeddings. We also configure the device setting, utilizing a GPU if available for faster computation, or defaulting to CPU otherwise.
Initialize Hugging Face Embeddings and FAISS Vector Store
embeddings = HuggingFaceEmbeddings(
model_name=modelPath,
model_kwargs=model_kwargs,
)
# Made up data, just for fun, but who knows in a future
vectorstore = FAISS.from_texts(
["Harrison worked at Alibaba Cloud"], embedding=embeddings
)
retriever = vectorstore.as_retriever()
We initialize an instance of HuggingFaceEmbeddings with our chosen model and configuration. Then, we create a vectorstore using FAISS, which allows us to perform efficient similarity searches in high-dimensional spaces. We also instantiate a retriever that will fetch information based on the embeddings.
Set Up the Chat Prompt Template
template = """Answer the question based only on the following context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
Here, we define a chat prompt template that will be used to structure the interaction with the AI. It includes placeholders for context and a question, which will be dynamically filled during the execution of the chain.
Prepare the Tokenizer and Language Model
In the world of AI and natural language processing, the tokenizer and language model are the dynamic duo that turn text into meaningful action. The tokenizer breaks down language into pieces that the model can understand, while the language model predicts and generates language based on these inputs. In our journey, we're using Hugging Face's AutoTokenizer and AutoModelForCausalLM classes to leverage these capabilities. But it's important to remember that one size does not fit all when it comes to choosing a language model.
Model Size and Computational Resources
The size of the model is a critical factor to consider. Larger models like Qwen-72B have more parameters, which generally means they can understand and generate more nuanced text. However, they also require more computational power. If you're equipped with high-end GPUs and sufficient memory, you might opt for these larger models to get the most out of their capabilities.
On the other hand, smaller models like Qwen-1.8B are much more manageable for standard computing environments. Even this tiny model should be able to run on IoT and mobile devices. While they may not capture the intricacies of language as well as their larger counterparts, they still provide excellent performance and are more accessible for those without specialized hardware.
Task-Specific Models
Another point to consider is the nature of your task. If you're building a conversational AI, using a chat-specific model such as Qwen-7B-Chat might yield better results as these models are fine-tuned for dialogues and can handle the nuances of conversation better than the base models.
Cost of Inference
Larger models not only demand more from your hardware but may also incur higher costs if you're using cloud-based services to run your models. Each inference takes up processing time and resources, which can add up if you're working with a massive model.
Qwen Series
Qwen-1.8B: A smaller model suitable for tasks requiring less computational power. Good for prototyping and running on machines without powerful GPUs.
Qwen-7B: A mid-size model that balances performance with computational demands. Suitable for a range of tasks, including text generation and question-answering.
Qwen-14B: A larger model that can handle more complex tasks with greater nuance in language understanding and generation.
Qwen-72B: The largest model in the series, offering state-of-the-art performance for advanced AI applications that require deep language comprehension.
Qwen-1.8B-Chat: A conversational model designed specifically for building chatbots and other dialogue systems.
Qwen-7B-Chat: Similar to Qwen-1.8B-Chat, but with increased capacity for handling more complex dialogues.
Qwen-14B-Chat: A high-end conversational model capable of sophisticated dialogue interactions.
Qwen-72B-Chat: The most advanced conversational model in the Qwen series, providing exceptional performance for demanding chat applications.
Making the Choice
When deciding which model to use, weigh the benefits of a larger model against the available resources and the specific requirements of your project. If you're just starting out or developing on a smaller scale, a smaller model might be the best choice. As your needs grow, or if you require more advanced capabilities, consider moving up to a larger model.
Remember, the Qwen series is open-source, so you can experiment with different models to see which one fits your project best. Here's how the model selection part of the script could look if you decided to use a different model:
# This can be changed to any of the Qwen models based on your needs and resources
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen-7B", trust_remote_code=True)
model_name_or_path = "Qwen/Qwen-7B"
model = AutoModelForCausalLM.from_pretrained(model_name_or_path,
device_map="auto",
trust_remote_code=True)
We load a tokenizer and a causal language model from Hugging Face with the AutoTokenizer and AutoModelForCausalLM classes, respectively. These components are crucial for processing natural language inputs and generating outputs.
Create the Text Generation Pipeline
This pipeline is designed to generate text using a language model and a tokenizer that have been previously loaded. Let's break down the parameters and understand their roles in controlling the behavior of the text generation:
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=8192,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1
)
hf = HuggingFacePipeline(pipeline=pipe)
Explanation of Parameters in the Text Generation Pipeline:
max_new_tokens (8192): This parameter specifies the maximum number of tokens that can be generated in the output. Tokens can be words, characters, or subwords, depending on the tokenizer.
do_sample (True): When set to True, this parameter enables probabilistic sampling from the distribution of possible next tokens generated by the model. This introduces randomness and variety in the generated text. If set to False, the model would always pick the most likely next token, leading to deterministic and less varied outputs.
temperature (0.7): The temperature parameter controls how much randomness is introduced into the sampling process. A lower temperature value (closer to 0) makes the model more confident in its choices, resulting in less random outputs, while a higher temperature value (closer to 1) encourages more randomness and diversity.
top_p (0.95): This parameter controls nucleus sampling, a technique that considers only the most probable tokens with a cumulative probability above the threshold top_p. It helps in generating text that is both diverse and coherent, avoiding the inclusion of very low-probability tokens that could make the text nonsensical.
top_k (40): Top-k sampling limits the sampling pool to the k most likely next tokens. This further refines the set of tokens that the model will consider for generating the next piece of text, ensuring that the outputs remain relevant and coherent.
repetition_penalty (1.1): This parameter discourages the model from repeating the same tokens or phrases, promoting more interesting and diverse text. A value greater than 1 penalizes and thus reduces, the likelihood of tokens that have already appeared.
After setting up the pipeline with the desired parameters, the next line of code:
hf = HuggingFacePipeline(pipeline=pipe)
Wraps the pipe object in a HuggingFacePipeline. This class is a part of the LangChain framework and allows the pipeline to be integrated seamlessly into LangChain's workflow for building AI applications. By wrapping the pipeline, we can now use it in conjunction with other components of the LangChain, such as retrievers and parsers, to create more complex AI systems.
The careful selection of these parameters allows you to fine-tune the behavior of the text generation to suit the specific needs of your application, whether you're looking for more creative and varied outputs or aiming for consistently coherent and focused text.
Build and Run the RAG Chain
The below code snippet represents a complete end-to-end RAG system where the initial question prompts a search for relevant information, which is then used to augment the generative process, resulting in an informed and contextually relevant answer to the input question.
- Chain Construction:
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| hf
| StrOutputParser()
)
Here's what's happening in this part of the code:
A retriever is used to fetch relevant information based on the query. The retriever’s role is to comb through a dataset or a collection of documents to find the pieces of information that are most pertinent to the question being asked. This is likely using a vector database for efficiency.
RunnablePassthrough() is a component that simply passes along the question without any modification. This suggests that the chain is designed to handle the question directly, probably as it was entered by a user.
The prompt is not shown in detail here, but it likely serves as a template or a set of instructions that formats the input question and the retrieved context in a way that is suitable for the next stage in the pipeline, which is the Hugging Face model.
The hf variable represents the Hugging Face pipeline, which is presumably a pre-trained language model capable of generating responses. This pipeline will take the formatted input from the previous step and use its generative capabilities to produce an answer.
The StrOutputParser() is an output parser, and its job is to take the raw output from the Hugging Face pipeline and parse it into a more user-friendly format, presumably a string.
The use of the | (pipe) operator suggests that this code is using a functional programming style, specifically the concept of function composition or a pipeline pattern where the output of one function becomes the input to the next.
- Chain Invocation:
results = chain.invoke("Where did Harrison work?")
In this line, the chain is being invoked with a specific question: "Where did Harrison work?" This invocation triggers the entire sequence of operations defined in the chain. The retriever searches for relevant information, which is then passed along with the question through the prompt and into the Hugging Face model. The model generates a response based on the inputs it receives.
- Printing Results:
print(results)
The generated response is then parsed by the StrOutputParser() and returned as the final result, which is then printed to the console or another output.
Finally, we construct the RAG chain by linking the retriever, prompt template, Hugging Face pipeline, and output parser. We invoke the chain with our question, and the results are printed.

Conclusion: Your Gateway to AI Mastery
You've just taken a giant leap into the world of AI with RAG and LangChain. By understanding and running this code, you're unlocking the potential to create intelligent systems that can reason and interact with information in unprecedented ways.
Remember, this is only the beginning. The more you experiment and tinker with RAG, the deeper your understanding and the greater your ability to innovate.
This article was originally published onAlibaba Cloud Comunity.